Sign Up Now
Get Free Credits

Canopy Wave Chat
Integrated Open Models|Data Security|Faster
The Platform that Enables Al
Where Compute Meets Expertise

API: Simply Ship Open Models
High-quality|Advanced|Secure
Sign Up Now
Get Free Credits

Canopy Wave Chat
Integrated Open Models | Data Security | Faster
The Platform
that
Enables AI
Where Compute Meets Expertise

API: Simply Ship Open Models
High-quality | Advanced | Secure















Model Library
We have built an open-source model library covering all types and fields. Users can call it directly via API without additional development or adaptation.







Instantly allocated GPU resource and ready-to-go AI resource
End-to-End Secure Operations
Our proprietary GPU management platform offers real-time monitoring, health alerts, and resource optimization. Backed by 24/7 support, we ensure peak cluster performance and stability.
Customized Service
We provide dedicated AI infrastructure and offer full-lifecycle AI services—such as model fine-tuning and agent customization tailored to your needs—to drive enterprises toward faster, smarter, and more cost-effective growth.
Canopy Wave Private Cloud
Best GPU cluster performance in the industry. With 99.99% up-time. Have all your GPUs under the same datacenter, your workload and privacy are protected.
Pay for What You Use
Only pay wholesale prices for the AI-related resources you actually consume. No hidden fees.
NVIDIA GB200 & B200, H100, H200 GPUs now available
NVIDIA GB200 NVL72
$9/GPU/hr

- • 72 Grace CPU + 72 Blackwell GPUs
- • 20.48 TB/s GPU-to-GPU interconnect
- • 8 HBM3e 192GB per GPU
- • 1.8TB/s memory bandwidth per GPU
- • Up to 144 MIGs @ 12GB each
Providing secure and efficient solutions for different use cases

AI Model Training
- Accelerate AI training with powerful computing power and low-latency networks.
- Applied in NLP, computer vision, recommendations, and autonomous driving.
Learn More>

Inference
- Scalable and secure AI inference powered by high-performance virtual machines.
- Applied in real-time search, recommendations, speech, and vision applications.
Learn More>

Rendering
- High-frame throughput and ultra-low latency with GPU and CPU-based rendering engines.
- Applied in gaming, simulation, virtual production, and design visualization.
Learn More>

GB200 Cluster Network solution
- A turnkey GB200 supercluster engineered for 24/7 production, featuring self-managing and self-monitoring capabilities.
Learn More>

Networking Hardware Solution
- Provide comprehensive network hardware solutions, including Switches, NICs, Transceivers, etc.
- Serving enterprise, data center, and edge computing with reliable, scalable infrastructure.
Learn More>

AI Model Training
Learn More>

Inference

Rendering

GB200 Cluster Network solution

Networking Hardware Solution
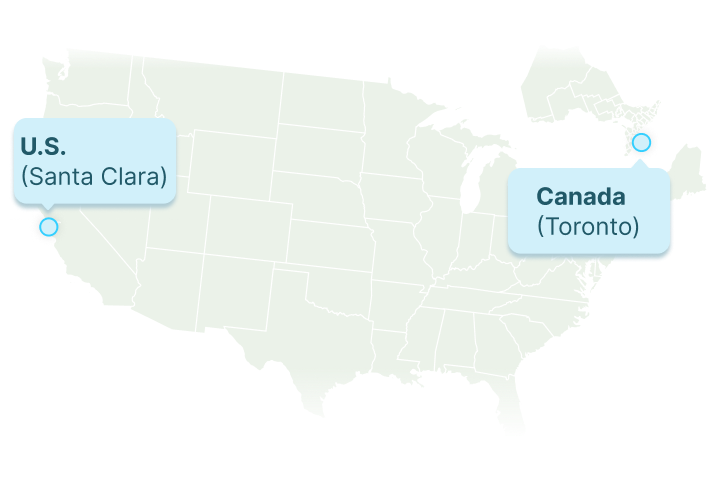
Powered By Our Global Network
Our data centers are powered by canopywave global, carrier-grade network — empowering you to reach millions of users around the globe faster than ever before, with the security and reliability only found in proprietary networks.
Explore Canopy Wave
Trust, A Core Requirement of AI
We build our values around Open, High-Quality, and Trust, by James Liao,Founder and CTO
The Rise of Enterprise AI: Trends in Inferencing and GPU Resource Planning
AI Agent Summit Keynote by James Liao @Canopy Wave
Accelerating Protein Engineering with Canopy Wave's GPUaaS
Foundry BioSciences Case Study
How to Run the GPT-OSS Locally on a Canopy Wave VM
Step-by-step guide for local deployment
Canopy Wave GPU Cluster Hardware Product Portfolio
This portfolio outlines modular hardware components and recommended configurations
