

GB200 Cluster with
RoCEv2 High
Performance
Network Solution
Low Latency | High Throughput | Optimized for AI and HPC
Challenges
Prolonged R&D Cycles
Training trillion-parameter models takes months.This severely slows algorithm iteration and delays time-to-market.
Performance Bottlenecks
Network latency between GPUs is the key bottleneck.This leads to idle GPUs and low MFU (Model FLOPs Utilization).
Operational Complexity
Deploying and managing large AI clusters is time-consuming and labor-intensive.This slows business responsiveness and makes troubleshooting difficult.
Solution & Performance
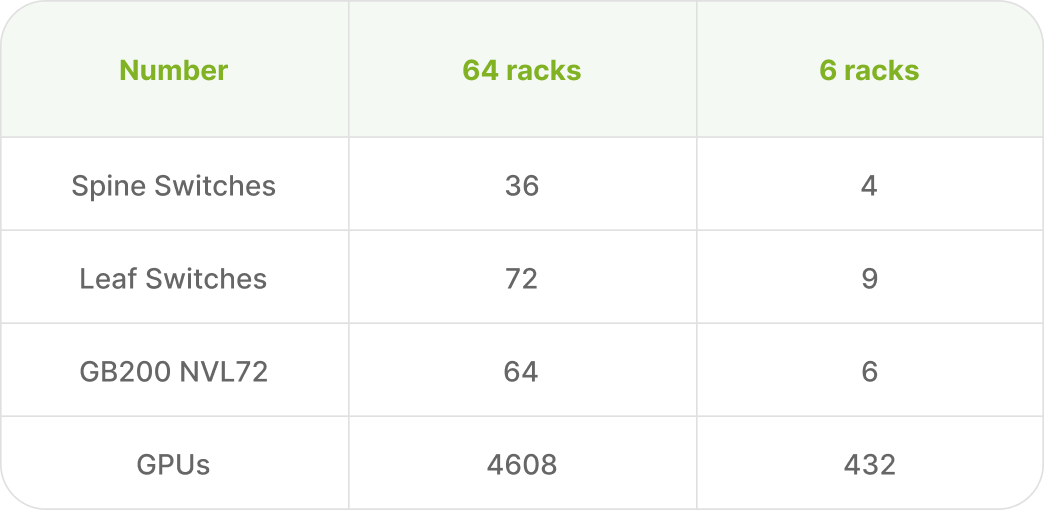
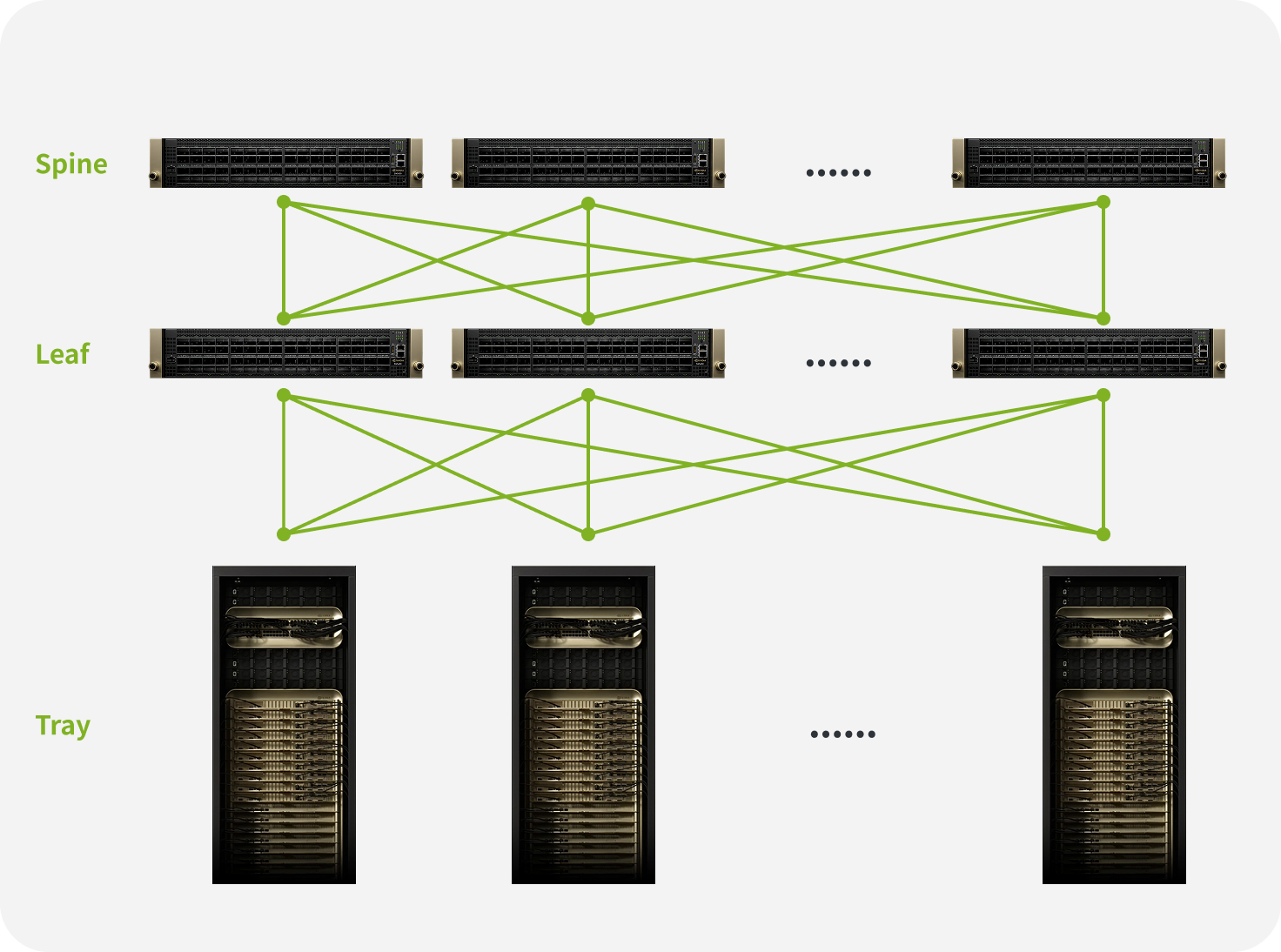
Overview of the Network Topology Diagram
A turnkey GB200 supercluster engineered for 24/7 production, featuring self-managing and self-monitoring capabilities
<10μs
Latency
99.999%
Reliability
400Gbps
Throughput
Benefits
GB200 GPU Clusters to Shorten R&D Cycles
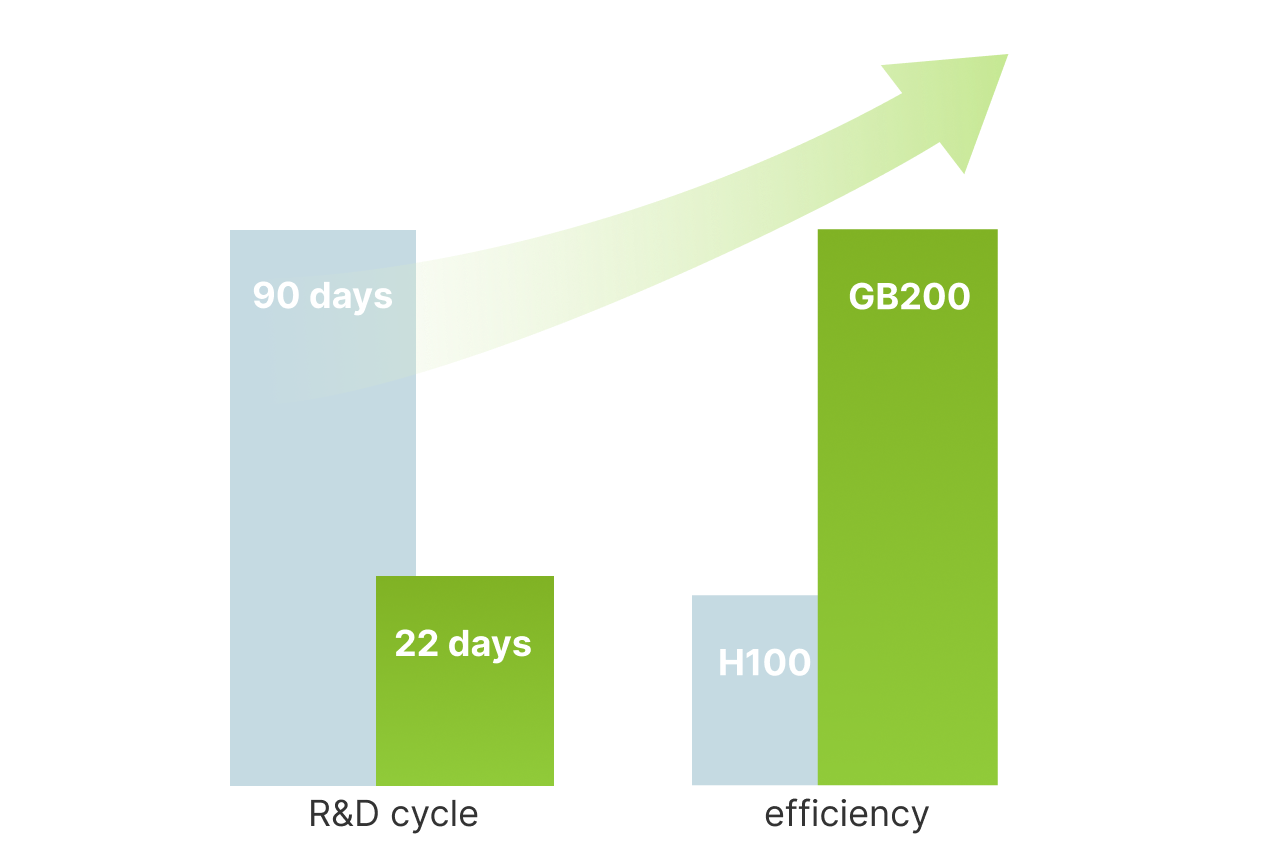
4× Faster Model Training
Reduced training time for a 1.8T model from 90 days to just 22, which is 4 times more efficient than the H100 cluster
RoCEv2 and NVLink breaks through performance bottlenecks
Slashed network latency by 60%, nearly eliminating compute idle time.
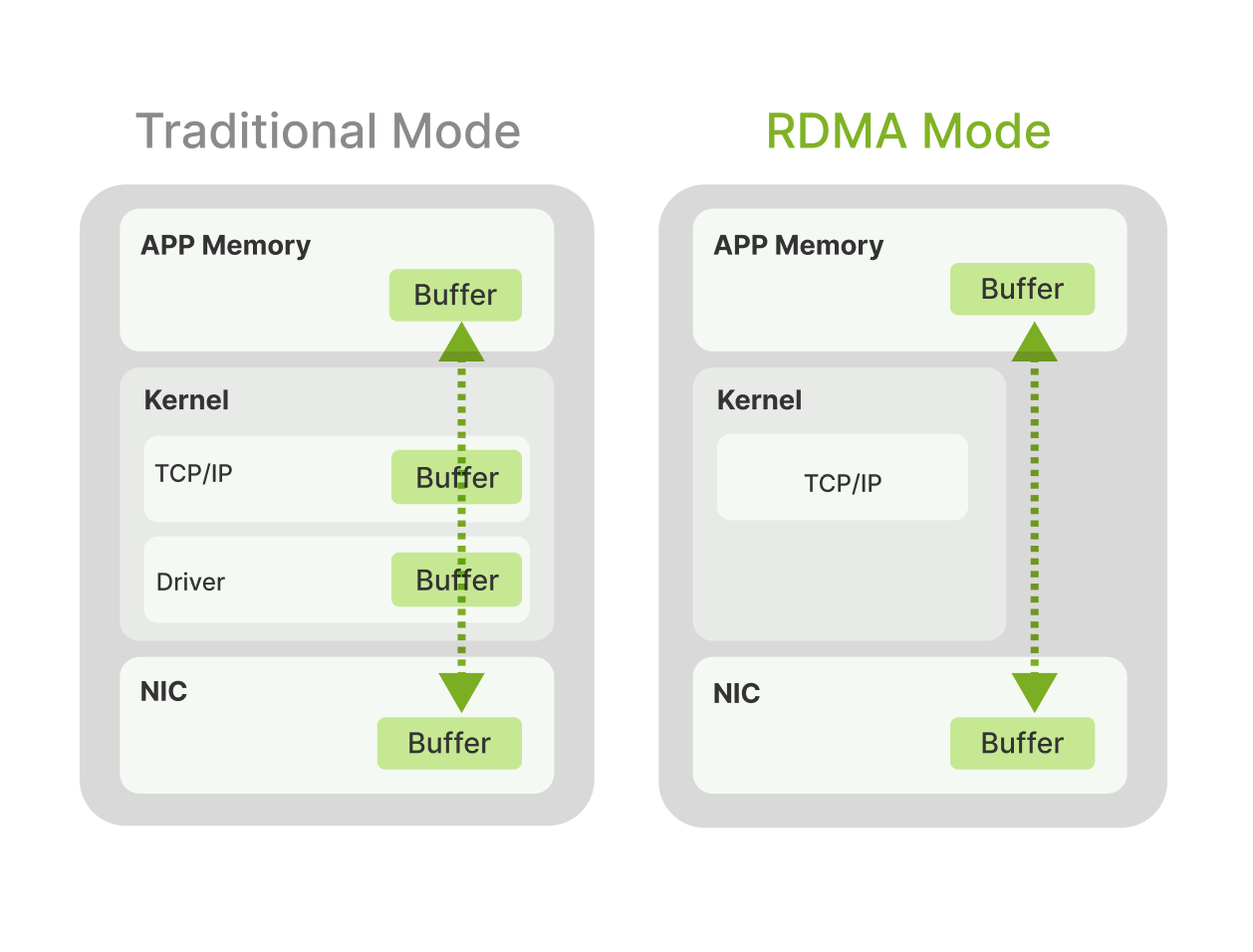
Ultra-Low Latency RoCEv2 Fabric
Utilizes RDMA for direct, kernel-bypass data transfer, minimizing latency and CPU load.
Ensures efficient, non-blocking communication between any two GPUs across the cluster.
Unified High-Bandwidth GPU Domain
Each NVL72 rack operates as a single, massive GPU with 1.8 TB/s of all-to-all NVLink bandwidth.
Eliminates all communication bottlenecks within the rack.
Operation & Support
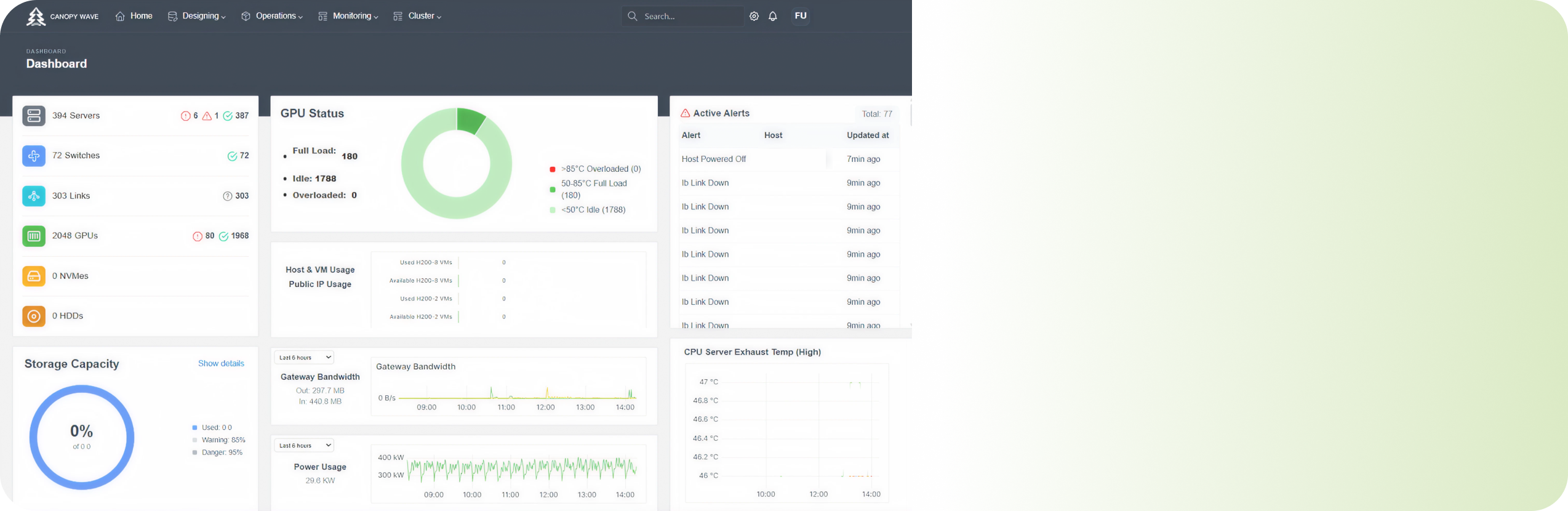
Intelligent End-to-End Monitoring
How
A unified platform integrates deep telemetry from all components (GPU, NVLink, Network).
Benefit
AI-driven analytics proactively detect anomalies and bottlenecks before they impact training jobs.


24/7 Proactive Expert Support
How
Engineers with deep experience with NVIDIA GPUs and software provide constant, around-the-clock system monitoring.
Benefit
Immediate remote intervention ensures maximum uptime and uninterrupted training.

Deployment Process
Planning & Design
Develop comprehensive documentation based on the client's data center topology, including detailed cabling plans and an IP addressing scheme.

Deployment
Rack switches, connect all physical cabling, and install GB200 NICs.
Configuration & Validation
Configure RoCEv2 parameters and conduct performance stress tests, followed by a final test report.
Acceptance & Handover
Provide precise acceptance criteria and deliver upon meeting the standards.
Resources
Tutorials
NVIDIA H100 vs H200 vs B200: Which GPU for Your Workload
Case Studies
Accelerating Protein Engineering with Canopy Wave's GPUaaS
Docs
Canopy Wave GPU Cluster Hardware Product Portfolio
Ready to get started?
Have a question about solution that you are interested in? Fill in the form and we’ll respond to you promptly.