AI Model Training
Utilize the Lastest and Most Powerful GPUs to Maximize Your Training Speed
Benefits & Performance
Powered by
Premium GPU Clusters
Canopy Wave features NVIDIA's latest generation GPU clusters, fully covering the GB200, B200, H200, and H100 .
Near-Bare-Metal
Performance Experience
A dedicated, optimized virtual machine architecture minimizes performance overhead to near zero.
Flexible
On-Demand Usage
Nodes are available instantly, no waiting required; billing is precise to the minute based on actual usage time.
99.99%
Uptime
0.1ms
Latency
3200Gbps
Infiniband
State-of-the-art AI Infrastructure
Delivering Unmatched Computing Power for AI Training
Canopy Wave provides high-performance GPU clusters Powered by the latest NVIDIA GPUs, including B300, GB200, B200, H200, and H100.

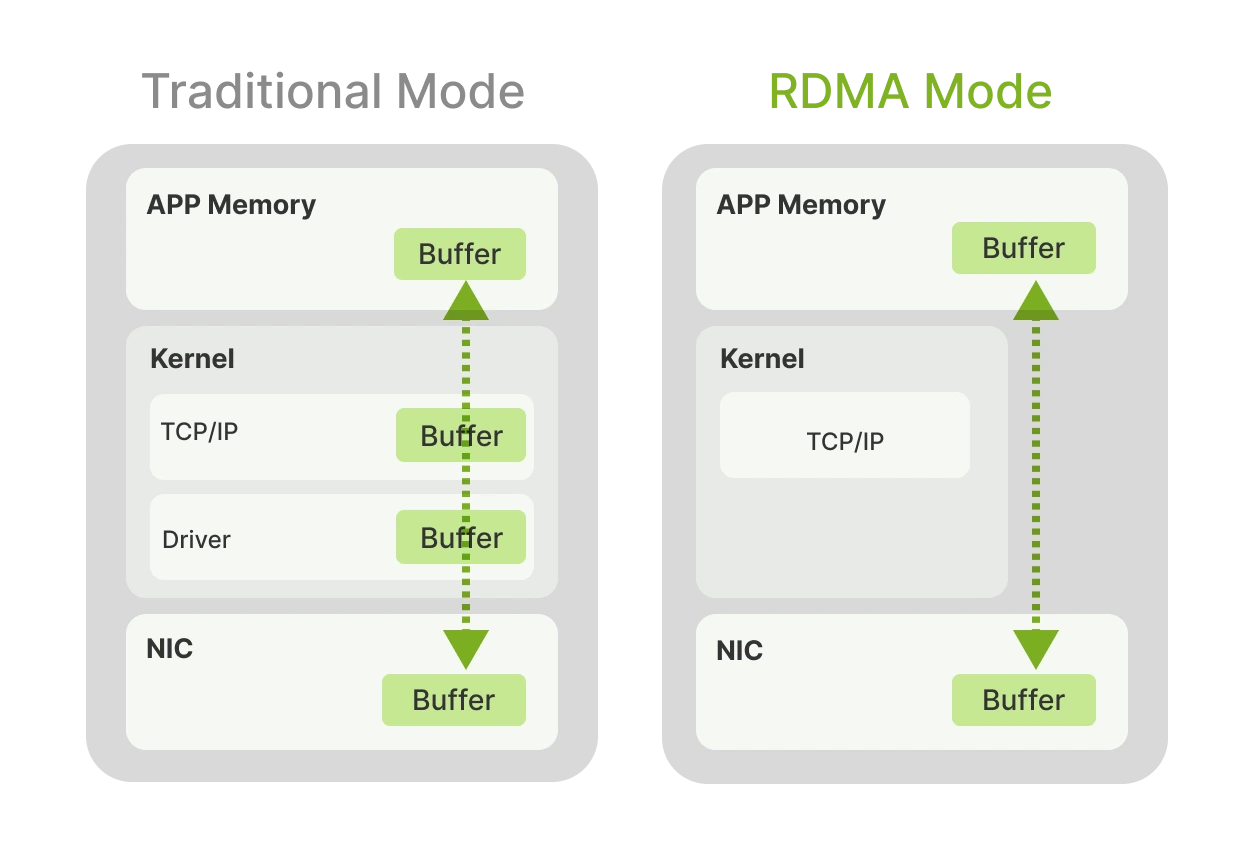
High-Performance Networking for AI Workloads
Maximize your AI training performance with our AI-optimized RDMA networking (utilizing InfiniBand and RoCEv2 technologies). Featuring a non-blocking topology with up to 3200G bandwidth, our network enables millisecond-level latency and seamless communication between large-scale GPUs, accelerating your training and boosting throughput.
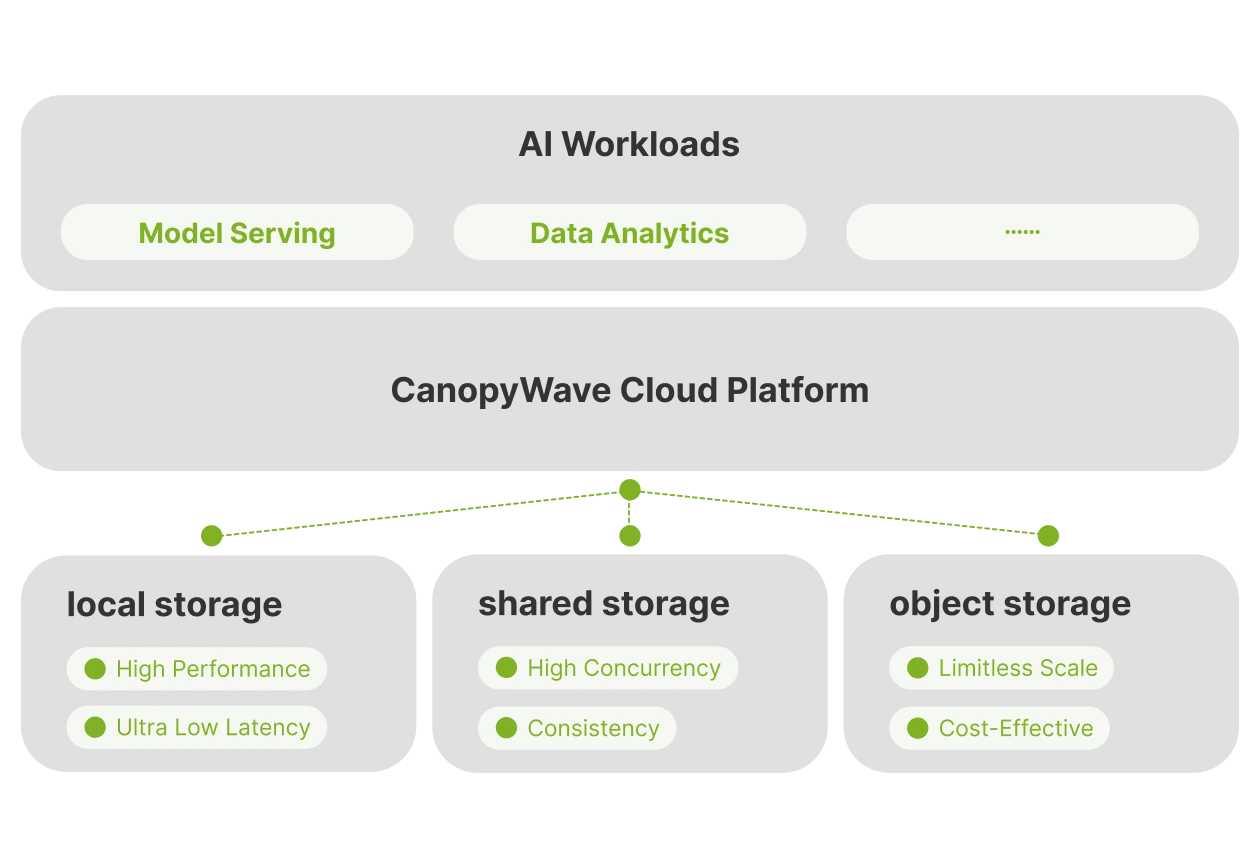
AI-Ready Storage Architecture
Our Flexible storage infrastructure is designed to support diverse AI workloads. Choose between local storage, shared storage, or object storage based on your performance, scalability, and data access requirements. Canopy Wave ensures your storage solution aligns perfectly with your workflow.
Virtual Machines
with Near-Bare-Metal Performance

Rapid Boot
From launch command to full system
readiness in minutes—start your
journey seamlessly.

Ultra-Low Latency
Reduces latency to 0.1ms using
lightweight compression (SDVoE) and
6G ULLC technologies.

Peak Performance
We utilize GPU-accelerated instances
and optimize the virtualization stack,
delivering performance comparable to
physical hardware.
On-demand Flexibility
and Per-minute Billing
No waiting in line, no paying for idle time. Whether you're a team or company needing to scale up at critical moments or wanting to avoid heavy capital investments in hardware, with Canopy Wave you can instantly launch powerful training nodes and pay only for what you use, down to the minute.
Operation & Support
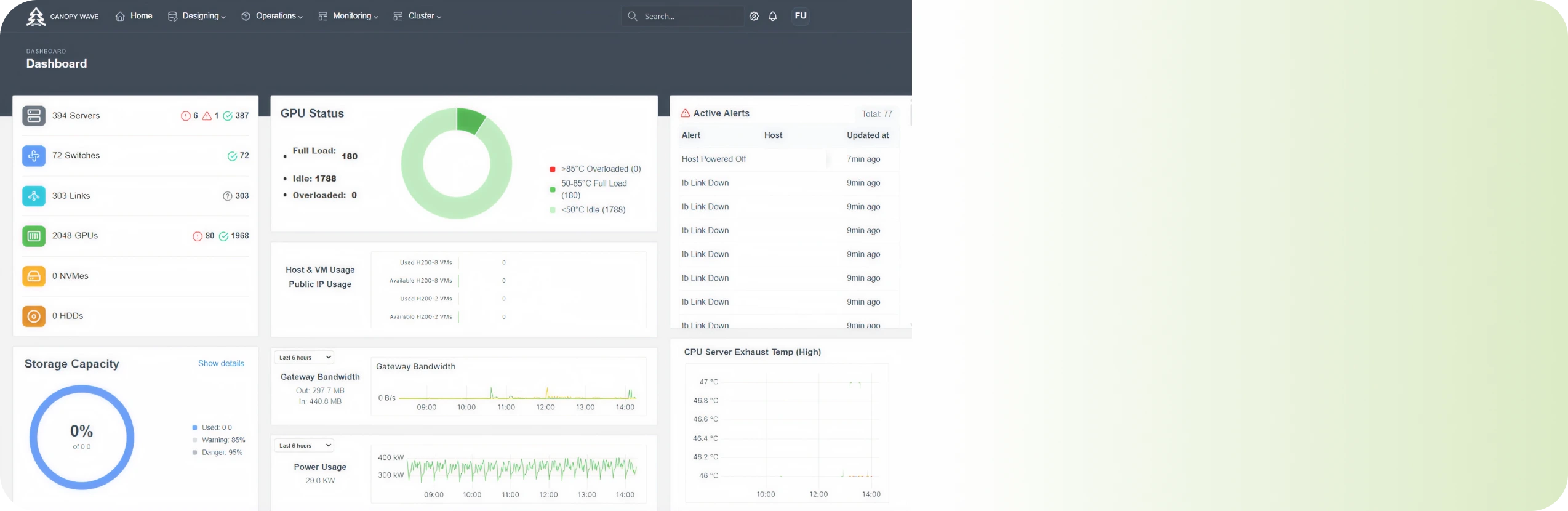
Intelligent End-to-End Monitoring
How
A unified platform integrates deep telemetry from all components (GPU, NVLink, Network).
Benefit
AI-driven analytics proactively detect anomalies and bottlenecks before they impact training jobs.

24/7 Proactive Expert Support
How
Engineers with deep experience with NVIDIA GPUs and software provide constant, around-the-clock system monitoring.
Benefit
Immediate remote intervention ensures maximum uptime and uninterrupted training.

Resources
Tutorials
How to Run the GPT-OSS Locally on a Canopy Wave VM
Case Studies
Accelerating Protein Engineering with Canopy Wave's GPUaaS
Docs
Canopy Wave GPU Cluster Hardware Product Portfolio
Ready to get started?
Have a question about solution that you are interested in? Fill in the form and we’ll respond to you promptly.