
Canopy Wave has launched the Kimi K2.5 model now!
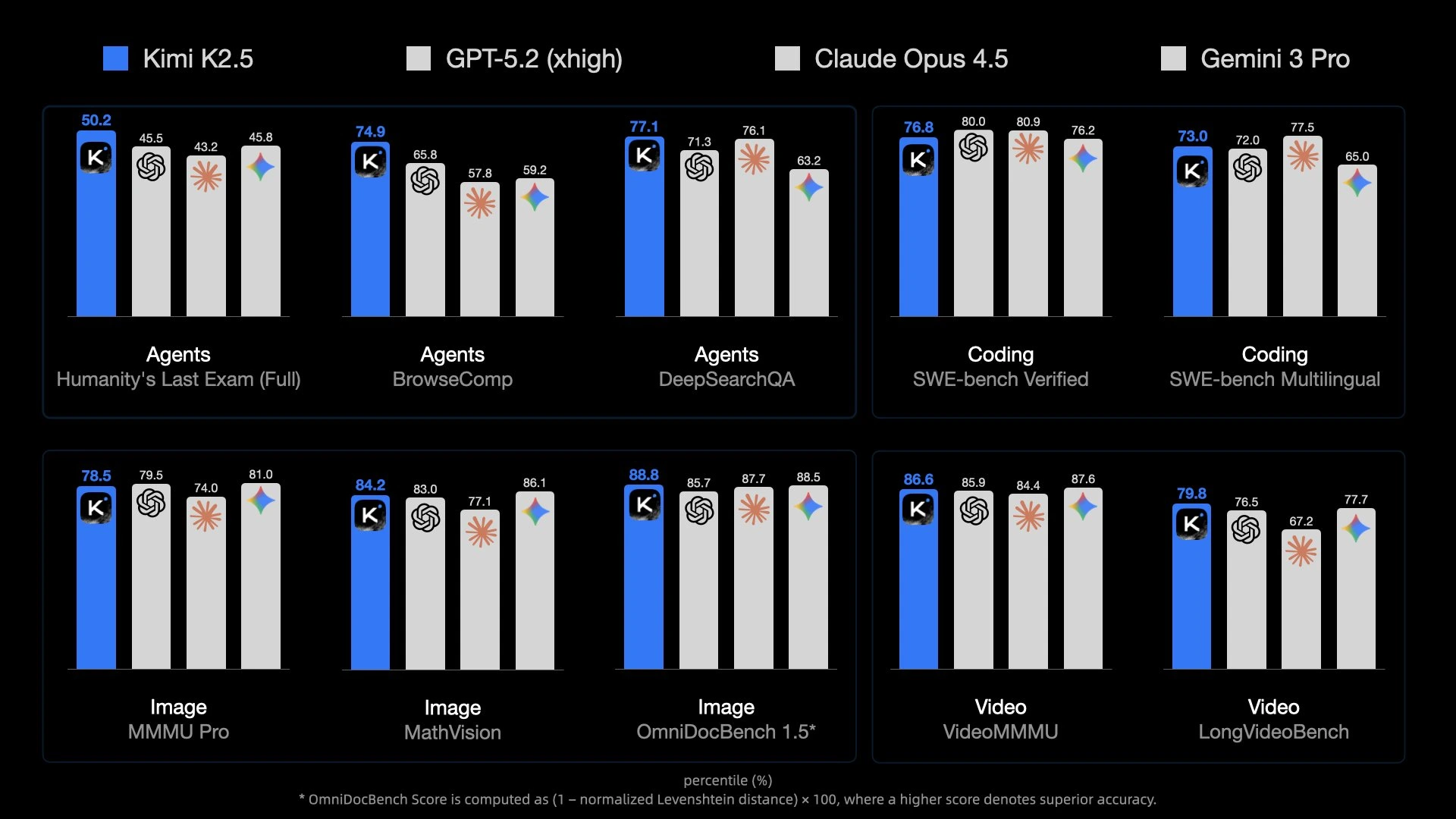
Kimi K2.5 is the latest flagship open-source model released by Moonshot AI. As a highly anticipated multimodal large language model in the current open-source ecosystem, Kimi K2.5 has achieved state-of-the-art performance among open-source models in Agent capabilities, code generation, visual understanding, and multiple general intelligence tasks.
Kimi K2.5 is now fully available on the Canopy Wave cloud platform. Users can access it through API calls or experience it for free in Canopy Wave Chat.
Part One: Model Features
1. Native Multi-modal Architecture
Kimi K2.5 natively supports text, image, and video inputs, combining visual understanding with strong reasoning for better performance in development, office, and content creation.
2. Agent Cluster: Multi-agent Cooperative System
Kimi K2.5 introduces a cutting-edge multi-agent system that can orchestrate up to 100 sub-Agents for complex tasks, executing up to 1,500 steps in parallel for a collaborative, team-like workflow.
3. Enhanced Coding Capabilities: Developer-Centric Open-Source Programming Model
Kimi K2.5 significantly improves coding performance across reasoning and generation benchmarks, enabling high-quality code generation, deep system analysis, debugging assistance, and seamless IDE integration.
Part Two: Why Choose Canopy Wave to Run Kimi K2.5
Canopy Wave is an inference platform built for developers and enterprise users, dedicated to fostering an open community, continuously onboarding top-tier open-source models, and powering them with robust enterprise-grade AI infrastructure — with the goal of becoming the world’s most reliable and highest-performing platform for open-source model inference.
1. Enterprise-Grade Performance & Stability Guarantee
We have rigorously tested Kimi K2.5 under high-concurrency and stability scenarios. In a stress test involving 40 concurrent connections and 80 sequential requests, the model achieved a 100% success rate with zero timeouts and zero abnormal responses.
In terms of performance, our Kimi K2.5 achieves an output speed of up to 756.65 tokens per second. Even under high-concurrency scenarios, it maintains low latency and stable responses. This outstanding performance is powered by Canopy Wave's model deployment on enterprise-grade GPUs, once again demonstrating that inference experience depends not only on the model itself, but also — and crucially — on the capabilities of the underlying AI infrastructure.

2. Key Performance Comparison: Leading in Multiple Metrics Against Mainstream Providers
Under the same rigorous test setup (30 concurrent users, 30 sequential calls per user, identical prompt), we conducted comparative tests with several major providers on OpenRouter — Together AI, Baseten, SiliconFlow, as well as the official Kimi.
The TTFT (P50) of Canopy Wave’s Kimi K2.5 is just 3.77s, representing an approximate 3.4× improvement over Baseten’s 12.92s and more than 4× improvement over Together AI’s 16.19s. Meanwhile, SiliconFlow’s TTFT (P50) is 38.4s and the official Kimi is 21.27s, meaning Canopy Wave achieves roughly 10× and 5.6× speedups, respectively. This indicates that for the majority of requests, Canopy Wave can start generating responses much faster.
The advantage is even more pronounced at high-percentile latency. Canopy Wave’s TTFT (P95) remains consistently under 6.0s, whereas Together AI reaches 41.76s—nearly 7 times slower—and Baseten is close to 23s, showing a roughly 4-fold difference. SiliconFlow’s TTFT (P95) reaches 127.58s, and the official Kimi is 43.93s. In contrast, Canopy Wave exhibits a more concentrated latency distribution under high-load and complex request scenarios, highlighting its clear advantage in stability.

In addition to its excellent first-token latency (TTFT), Canopy Wave’s Kimi K2.5 continues to lead in Output TPS and Total TPS:
The Output TPS reaches 533 tokens/s, significantly higher than Baseten’s 260.47 tokens/s and SiliconFlow’s 353.45 tokens/s, and far exceeding Together AI’s 144.1 tokens/s and the official Kimi’s 49.89 tokens/s. Within the same time frame, Canopy Wave can generate more content, with its advantages particularly evident in long-text outputs and high-concurrency scenarios.
The Total TPS reaches 1,078.13 tokens/s, over 2.7× that of Baseten (405 tokens/s) and 3.7× that of Together AI (293.30 tokens/s), as well as more than 2× higher than SiliconFlow (518.16 tokens/s) and over 5× higher than the official Kimi (197.45 tokens/s). This reflects Canopy Wave’s superior throughput efficiency across the entire inference process, including both the prefill and decode stages.

3. Pricing Advantage
In terms of pricing, Canopy Wave further lowers the barrier for users. Our Kimi K2.5 is priced at $0.5 per 1M input tokens and $2.8 per 1M output tokens. By comparison, the average pricing of Kimi K2.5 from major providers on OpenRouter is around $0.6 per 1M input tokens and $3.0 per 1M output tokens.

While ensuring performance and stability, Canopy Wave offers developers and enterprise users a more cost-effective option. We firmly believe that price should not be a barrier to exploring and using high-quality open-source models — this is also the core reason why Canopy Wave continues to invest in the open-source ecosystem and build an open community.
Part Three: Experience Kimi K2.5 Right Now
• Try Kimi K2.5 for free in Canopy Wave Chat
• Or access its model API
Start exploring the full potential of open-source models in real-world scenarios today.