
Unlimited Token Plan Officially Launched
If you're deploying OpenClaw or building your own one-person company, you've almost certainly faced these two pain points:
• Token costs keep rising, making bills unpredictable
• Usage limits hit unexpectedly, forcing core tasks to stop
Essentially, your AI productivity is held back by token costs.
Built exclusively for OpenClaw automation. Free your AI computing power and keep your OpenClaw running nonstop.
• Starting at $15.99/month – up to 90% cost savings vs. Claude
• The first truly unlimited token plan – No surprise bills, No service interruptions
• No request limits, up to 256 concurrent requests
• 21x faster inference speed than competitors
• 100% privacy protected
OpenClaw + Unlimited Tokens = Infinite Workforce
AI is no longer just a tool – it's a 24/7 AI workforce team:
• Sales Assistant: Track leads, write and follow up on emails, auto-update CRM
• Product Manager: Organize to-dos, write PRDs, summarize user feedback
• Financial Analyst: Generate reports, track KPIs, build forecasting models, identify trends
• Engineer: Review code, write docs, automate tests, manage GitHub workflows
• DevOps: Monitor infrastructure, manage deployments, optimize costs
These "Lobsters" run 24/7 without token limits.
You set the direction; they execute. You make decisions; they get everything done.
What you're building is no longer just a toolchain – it's your own automated one-person company.
Save Up to 90% Compared to Claude
Compared to closed models like Claude, in typical AI Agent scenarios (input/output ratio ~65:1), you can cut costs by 90%.
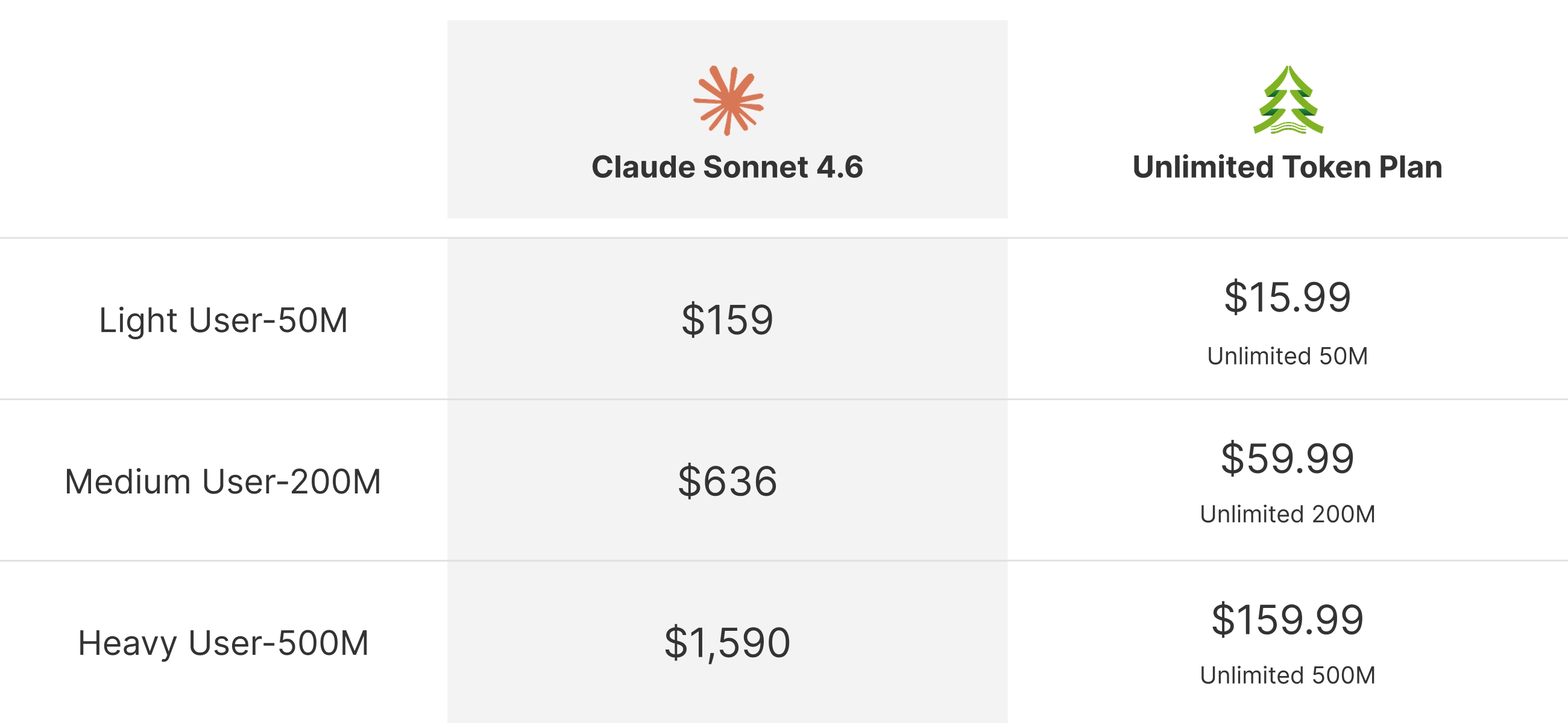
Whether you're new to OpenClaw or a seasoned "Lobster expert," the Unlimited Token Plan slashes your costs by 90%. No hidden fees, no service interruptions, just the best multimodal open-source model powering your OpenClaw around the clock.
The Perfect Choice for Your One-person Company
In the OpenClaw ecosystem, the model isn't just a tool – it's the engine of your entire system.
A model truly built for OpenClaw needs: strong reasoning, reliable tool calling, multimodal capabilities, and 24/7 runtime stability. Canopy Wave's highly optimized multimodal Kimi K2.5 was made for this.
Blazing-Fast Inference: TTFT up to 21x Faster
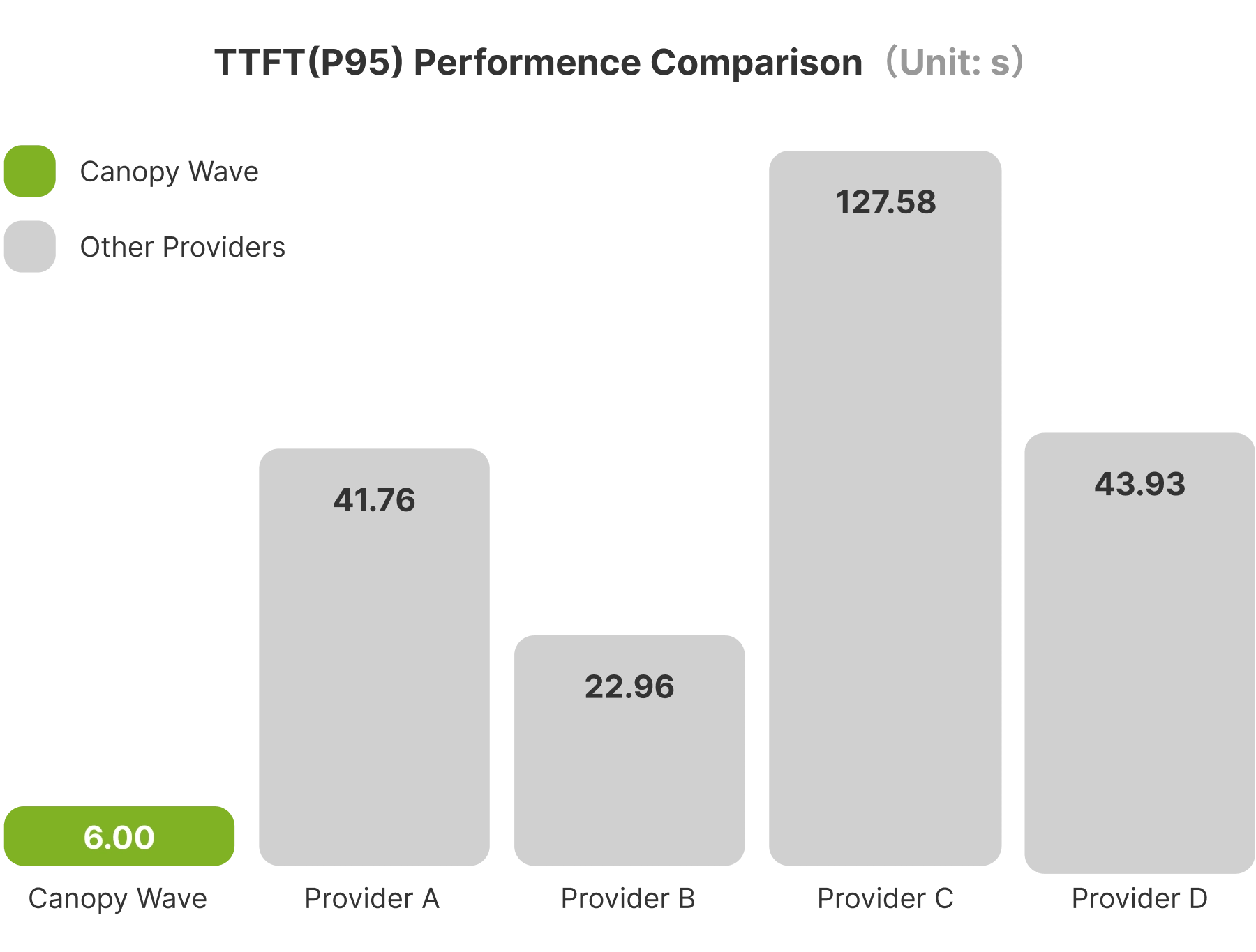
OpenClaw runs many real-time tasks: messaging, email handling, scheduling, browser operations, and data scraping – all highly sensitive to Time to First Token (TTFT).
Canopy Wave's optimized Kimi K2.5 pushes P95 TTFT to just 6 seconds, compared to 22.96s–27.58s from major OpenRouter providers – a 21x speed increase.
For OpenClaw users, this isn't just an upgrade – it's a paradigm shift.
Ultra-High Throughput: TPS up to 5x Higher
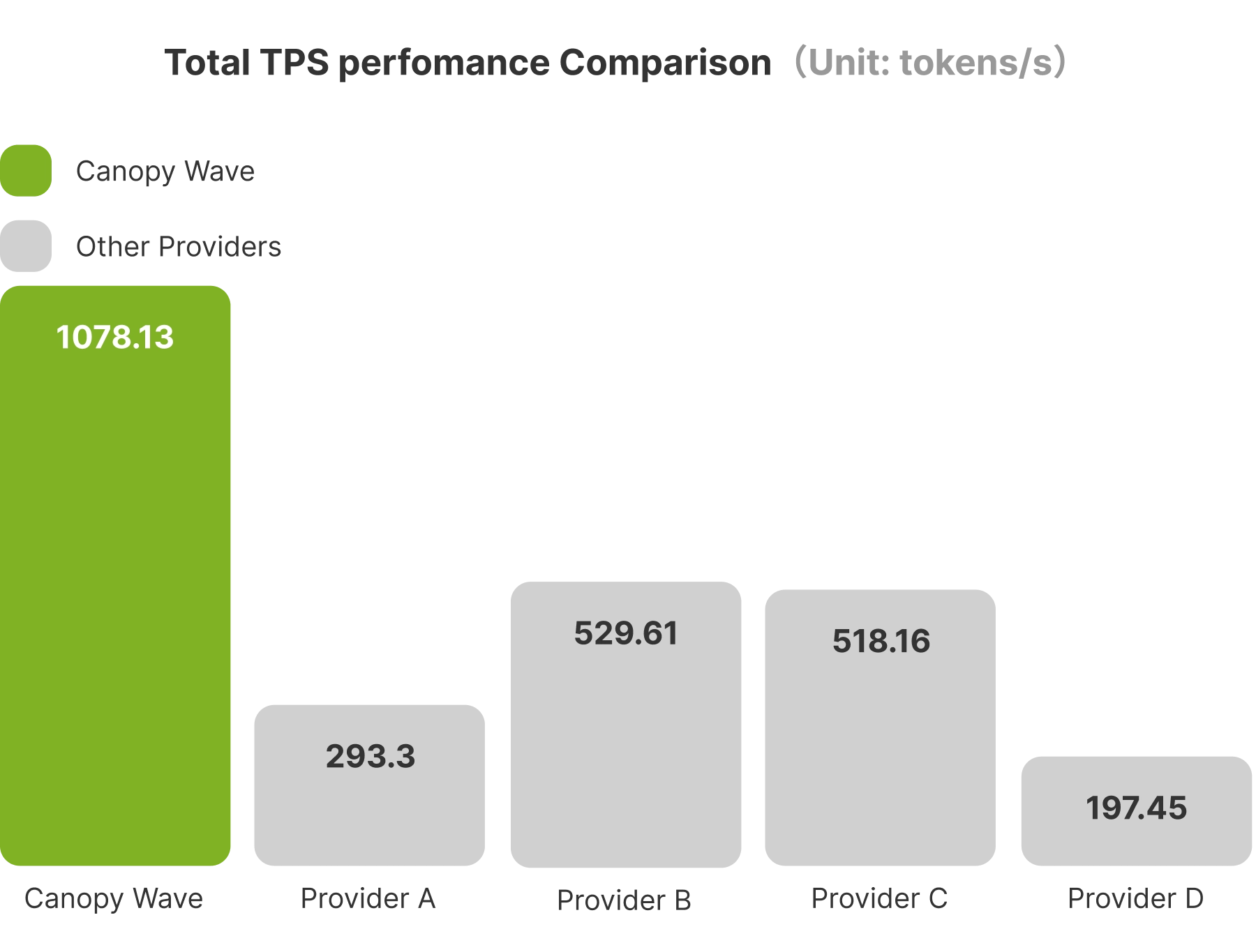
The real challenge of OpenClaw isn't a single Agent – it's running dozens or hundreds of "Lobsters" at once.
Canopy Wave's Kimi K2.5 delivers 1078.13 tokens/sec total TPS, nearly 5x higher than other providers (max ~529 tokens/sec).
Run up to 5x more Agents simultaneously, scale your Lobster Legion, and stay stable even under heavy load.
100% Data Privacy
Data security is foundational for AI infrastructure. Canopy Wave guarantees global users:
• Inference data is never stored
• Data is never used for model training
• No third-party access
• All inference runs under strict privacy and compliance frameworks
We protect your OpenClaw, from the ground up.

