
We’re launching Kimi K2.6 not just for a "stronger model" — but so you can use it confidently, use it freely, without stress over compute limits or bills.
Canopy Wave has launched the Kimi K2.6 model now!
Kimi K2.6 is the latest flagship open-source model from Moonshot AI. It supports ultra-long context, multimodal input, and orchestrates large-scale AI Agent collaboration. It excels at complex coding and automation tasks, delivering state-of-the-art performance in code generation, long-horizon task execution, and Agent cluster capabilities.
• Stronger reasoning
• More stable Agents
• Longer context windows
• Precise instruction following & fuzzy command understanding
• Enhanced full-modal perception

• Developers: Direct API access
Top-tier model power + flexible subscription plans = The future, within reach.
Full Upgrade: More Powerful Model, Same Pricing
The Unlimited Token Plan has completed a major upgrade: The plan is fully upgraded to Kimi K2.6 — at no extra cost.
What you now get:
• Over 4,000 tool call capabilities
• Long task execution running continuously for over 12 hours
• Support for 300 sub-Agents running simultaneously to complete 4,000 collaborative tasks
• Enable your OpenClaw & Hermes Agent to run autonomously for up to 5 days
• No request limits, no token usage caps
Save up to 90% of costs compared with Claude.

Enterprise-Grade Leading Performance
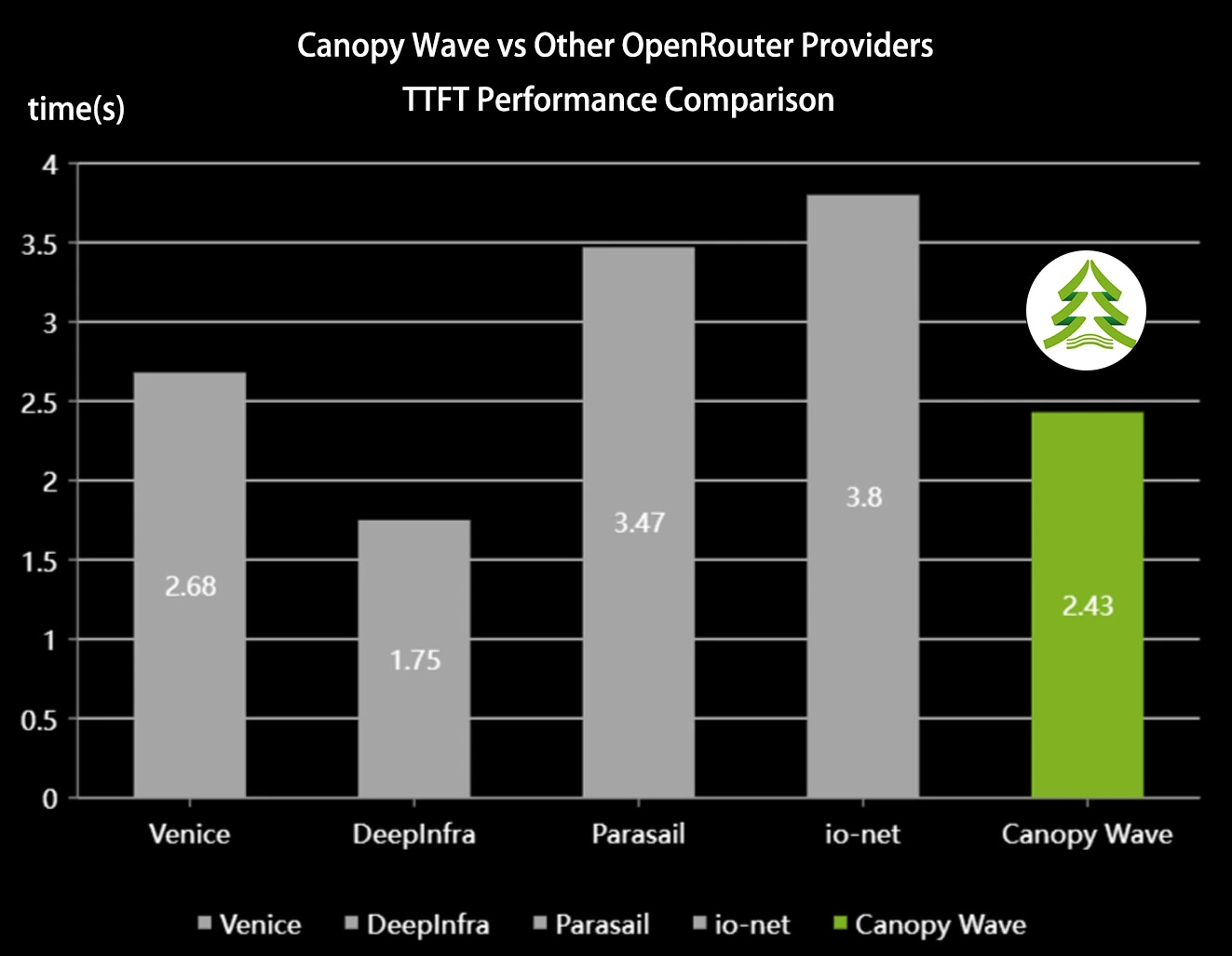
Test 1: TTFT
TTFT is a key indicator of inference responsiveness, directly affecting user experience. Canopy Wave delivers outstanding performance in this regard, achieving near industry-leading latency while significantly outperforming mainstream platforms with high tail latency.
• Canopy Wave: 2.43s (up to 1.5x performance improvement vs. mainstream providers)
• Venice: 2.68s
• DeepInfra: 1.75s
• Parasail: 3.47s
For most requests, Canopy Wave delivers near industry-leading time-to-first-token latency, while significantly outperforming mainstream platforms with high tail latency.
Test 2: Output TPS
Output TPS reflects the efficiency of content generation per unit time. Canopy Wave’s excellent performance in this test proves its strong capability in high-density content output, ranking in the top tier of generation efficiency among mainstream providers.
• Canopy Wave: 52.54 tokens/s (outperforming other providers by 1.45–3.6x)
• Venice: 29.53 tokens/s
• DeepInfra: 14.57 tokens/s
• Parasail: 14.5 tokens/s
This performance advantage makes Canopy Wave highly competitive in long-form text generation and multi-task scenarios, helping teams save valuable time in content creation and task execution.
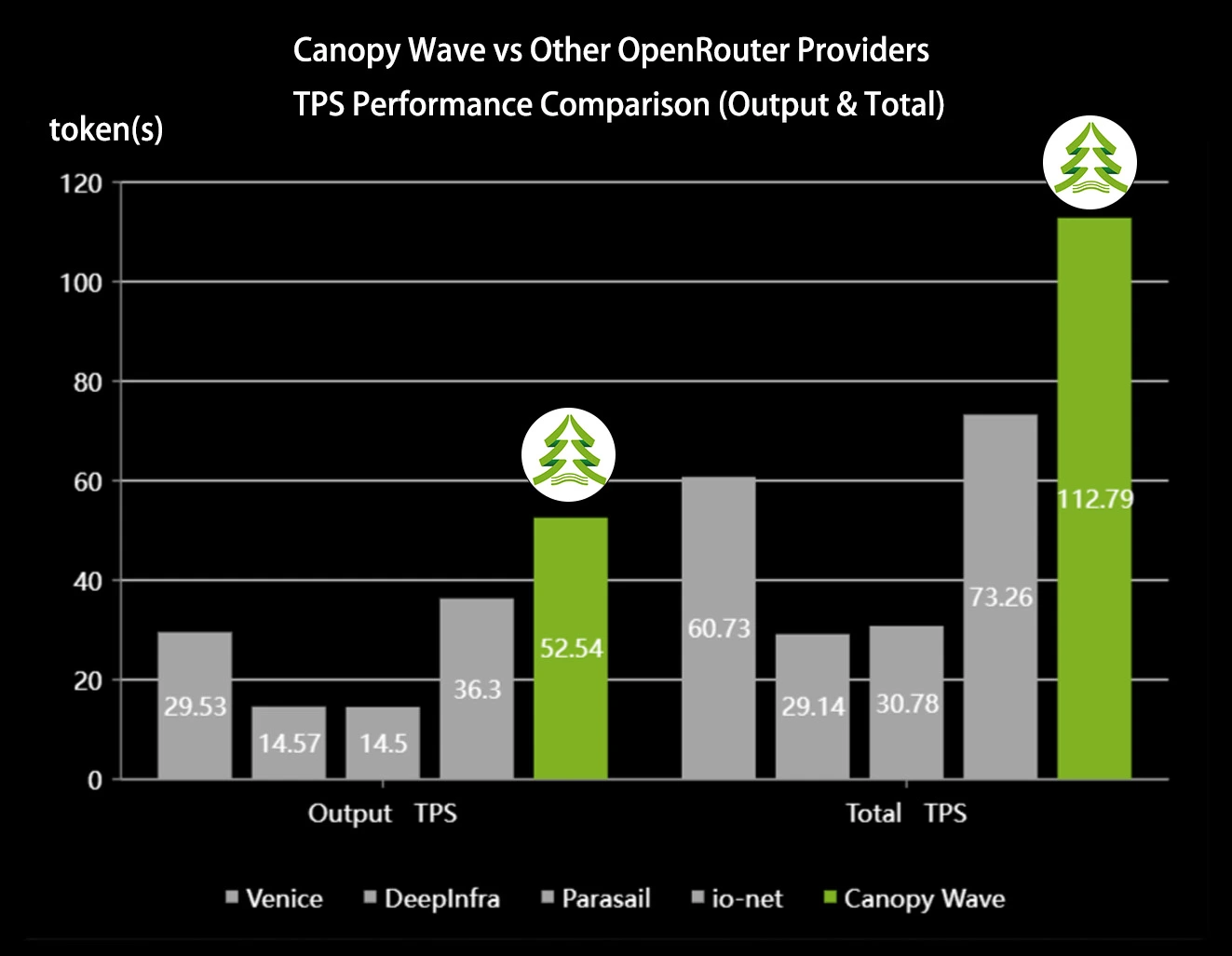
Test 3: Total TPS
Canopy Wave achieves a Total TPS of 112.79 tokens/s.
• Venice: 60.73 tokens/s (Canopy Wave 1.86x faster)
• DeepInfra: 29.14 tokens/s (Canopy Wave 3.87x faster)
• Parasail: 30.78 tokens/s (Canopy Wave 3.66x faster)
• io.net: 73.26 tokens/s (Canopy Wave 1.54x faster)
In terms of end-to-end inference throughput, Canopy Wave delivers consistently high-performance processing capabilities, outperforming multiple providers on OpenRouter. It is perfectly suited for large-scale Agent orchestration and long-chain task execution.
Try Kimi K2.6 Now
Join us to explore more real-world possibilities of open-source models. With Canopy Wave, you can build from zero to one and fully unlock the true potential of open-source AI models.

