
I. What Revolutionary Improvements Does B300 Bring?
The NVIDIA B300, built on the Blackwell Ultra architecture and officially shipping in January 2026, stands as the most powerful single-GPU computing platform NVIDIA has ever released. Compared to the previous-generation Hopper architecture, B300 delivers a qualitative leap across multiple key metrics.
From an architectural standpoint, Blackwell Ultra is far more than a simple process node upgrade — it is a deep optimization by NVIDIA specifically for large language model (LLM) inference. With 14 petaFLOPS of sparse FP4 compute, 288GB of HBM3e memory, and 8 TB/s of memory bandwidth, these figures translate into the ability for a single GPU to host models with vastly larger parameter counts while driving significantly higher inference throughput.
For AI enterprises evaluating GPU options, the arrival of B300 brings several critical changes:
• Larger models on a single card: 288GB of memory means a single B300 can load a 70B-parameter model (at FP16 precision) while leaving over 100GB available for KV Cache.
• Significantly reduced inference costs: Compared to the H100, B300 achieves an 11–15× increase in inference throughput.
• Support for longer contexts: The expanded memory capacity allows the full KV Cache of long-text sequences to be retained, avoiding performance degradation due to memory constraints.
II. What Are the Specifications of the NVIDIA B300 GPU?
| GPU | Architecture | FP8 (Dense) Compute | Memory | Memory Bandwidth | NVLink |
|---|---|---|---|---|---|
| B300 | Blackwell Ultra | 7000 TFLOPS | 288GB HBM3e | 8 TB/s | 1.8 TB/s |
| B200 | Blackwell | 4500 TFLOPS | 192GB HBM3e | 8 TB/s | 1.8 TB/s |
| H200 | Hopper | 756 TFLOPS | 141GB HBM3e | 4.8 TB/s | 900 GB/s |
| H100 | Hopper | 756 TFLOPS | 80GB HBM3e | 3.35 TB/s | 900 GB/s |
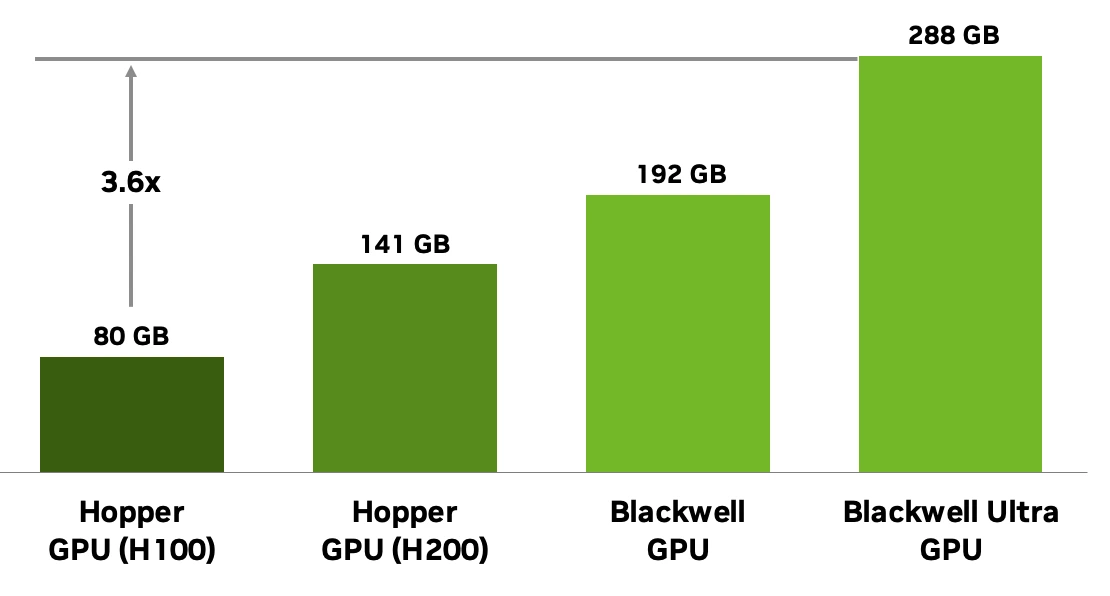
According to NVIDIA's official technical documentation, the B300 offers 2× the memory capacity of the H200 and 3.6× that of the H100; the B200 delivers roughly 6× the FP8 inference performance compared to the H200. This massive generational leap is primarily driven by the dual optimization of compute density and memory subsystems in the Blackwell architecture.
For enterprises considering purchasing B300 GPUs to build on-premises data centers, a critical factor to note is the B300's TDP (Thermal Design Power) of 1,400W, which mandates direct liquid cooling (DLC) for production deployment. Compared to the air-cooled solutions of the H200 and H100, this adds infrastructure complexity, but for enterprise deployments pursuing peak performance, it is a necessary reality.
An 8-GPU DGX B300 system has a peak power draw of approximately 14kW — equivalent to the consumption of two H100 DGX systems. Enterprises must fully account for power and cooling capacity when planning their facilities. Therefore, rather than purchasing hardware outright, many businesses may prefer to access B300 GPUs through cloud services, delegating power and thermal challenges to the cloud provider and saving significant operational overhead.
• The NVIDIA B300 GPU features 288GB of HBM3e memory.
• It delivers up to 7,000 TFLOPS of FP8 compute performance.
• Memory capacity is increased by 2× compared to the H200.
• Memory capacity is increased by 3.6× compared to the H100.
III. Blackwell Ultra vs. Hopper: Generational Performance Comparison
| Metric | B300 vs. H200 |
|---|---|
| Prefill Throughput (ISL=2k) | 8× |
| Short Output Throughput (ISL=2k, OSL=128) | 20× |
These figures indicate that, for typical online inference scenarios, the B300 delivers significantly higher concurrency than the H200. Under the same service level agreement (SLA), enterprises can handle equivalent traffic volumes with far fewer GPU resources, thereby substantially reducing inference costs.
IV. B300 Use Cases and Challenges
The B300 is particularly well-suited for the following scenarios:
1. Large-scale inference services: Online inference for 70B+ parameter models, with single-GPU throughput reaching 100,000+ tokens/s.
2. Inference-intensive workloads: Models optimized for inference such as DeepSeek and the Kimi series, where 288GB of memory can fully retain the KV Cache.
3. Multi-node training clusters: With 6.4 Tbps of GPU interconnect bandwidth, effectively supporting the communication demands of distributed training.
4. 400B+ parameter model deployment: An 8-GPU DGX B300 provides 2.3TB of total memory, enabling full loading of 400B-parameter models.
• Liquid cooling requirement: Direct liquid cooling (DLC) is mandatory, increasing infrastructure investment.
• High power consumption: At 1,400W per card, data center power and cooling capacity must be carefully evaluated.
• Software ecosystem: Requires CUDA 12.x, cuDNN 9.x, and TensorRT-LLM 0.15+ support.
| GPU | Memory | Bandwidth | Inference Performance | Suitable Scenarios |
|---|---|---|---|---|
| H100 | 80GB | 3.35 TB/s | Baseline | Mid-size LLMs |
| H200 | 141GB | 4.8 TB/s | 2-3× | Long-context |
| B300 | 288GB | 8 TB/s | 8-20× | Inference models |
The launch of the NVIDIA B300 (Blackwell Ultra) marks the entry of AI infrastructure into a new era of performance. With 288GB of HBM3e memory, 8 TB/s of bandwidth, and 14 petaFLOPS of compute, the B300 provides a powerful hardware foundation for large model inference.

